phpsnoopy的最佳实践:实现自动化网站数据提取的完整指南

在当今信息化快速发展的时代,网站数据提取已经成为许多企业和研究人员关注的焦点。随着数据需求的增加,自动化网站数据提取的工具和方法也应运而生。phpSnoopy是一个广受欢迎的PHP类库,专门用于抓取网页和提取数据。本文将深入分析phpSnoopy的最佳实践,帮助用户高效地进行自动化网站数据提取。
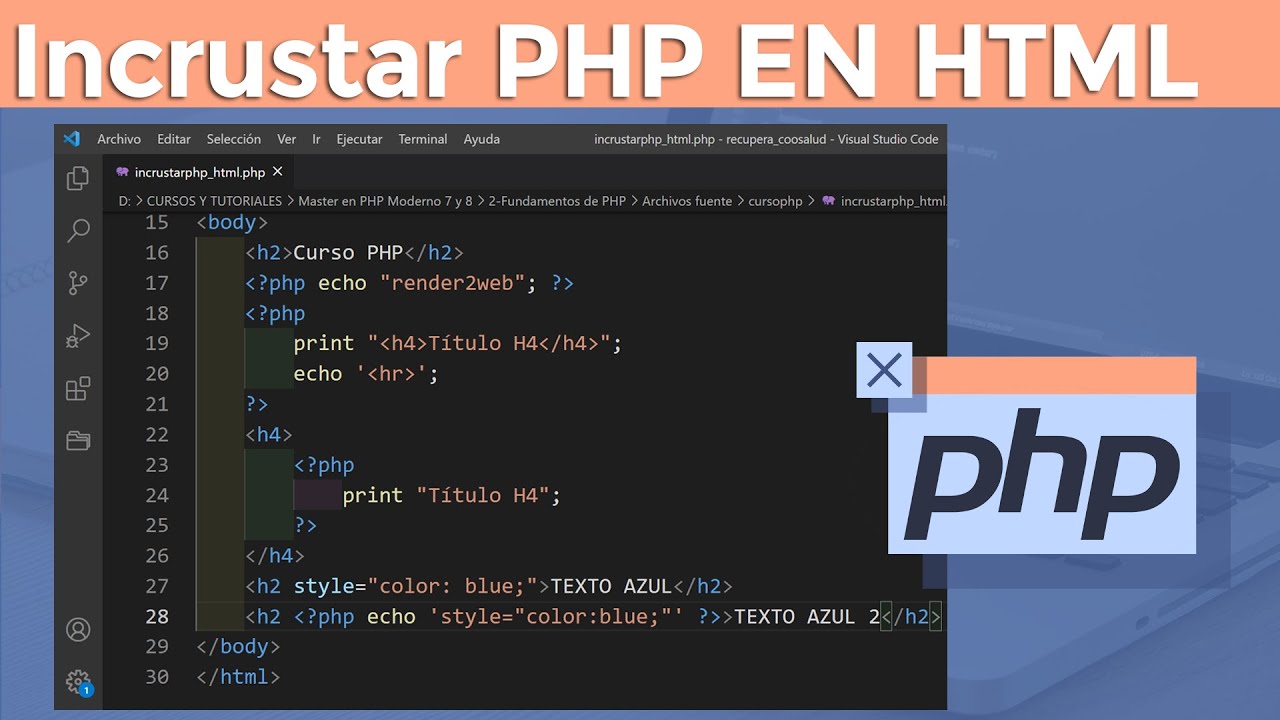
必须了解phpSnoopy的基本功能。phpSnoopy是一个轻量级的HTTP客户端,能够模拟浏览器的请求行为,获取网页内容。它具有简单易用的API,用户只需创建一个Snoopy对象,就可以发送GET或POST请求并接收响应。通过解析HTML返回的内容,用户可以提取所需数据,从而实现自动化的数据抓取。
在使用phpSnoopy进行网站数据提取时,以下几个最佳实践值得注意:
1. 合理设置请求头
许多网站会对请求进行验证,以防止恶意程序或爬虫抓取数据。为了提高访问的成功率,用户应设置合适的请求头,例如User-Agent和Referer。User-Agent可以模拟真实浏览器的请求,让目标网站误以为请求来源于普通用户。Referer则可以指定请求来源,进一步提升成功率。一个示例代码如下:
$snoopy = new Snoopy();$snoopy->agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0";$snoopy->referer = "http://www.example.com";$snoopy->fetch("http://www.targetsite.com");
2. 控制抓取频率
过于频繁的请求可能导致被目标网站封禁。因此,合理控制抓取频率是必要的。可以通过引入随机等待时间来避免被识别为爬虫。例如,可以使用sleep()函数或usleep()函数在请求之间插入延迟:
sleep(rand(1, 5)); // 随机等待1到5秒
3. 错误处理和重试机制
在爬取过程中,可能遇到网络错误、超时或返回错误状态码等问题。因此,建立有效的错误处理机制至关重要。可以使用try-catch结构捕获异常,并在捕获到特定错误时进行重试。例如,如果请求失败,可以设置最大重试次数,避免程序因偶然错误而中断:
$max_retries = 3;for ($i = 0; $i < $max_retries; $i++) { $snoopy->fetch("http://www.targetsite.com"); if ($snoopy->status == 200) { break; // 请求成功,跳出循环 }}
4. 数据解析与存储
获取网页内容后,下一步是提取所需数据。phpSnoopy可以与DOMDocument或类似的HTML解析库结合使用,方便地提取特定的HTML标签或属性。提取到的数据可以存入数据库或文件中,以便后续分析。
$html = $snoopy->results;$dom = new DOMDocument();libxml_use_internal_errors(true); // Suppress parsing errors$dom->loadHTML($html);$xpath = new DOMXPath($dom);$titles = $xpath->query("//h1");foreach ($titles as $title) { echo $title->textContent . "
"; // 输出标题内容}
5. 遵守网站的robots.txt文件
在进行数据抓取时,需尊重目标网站的robots.txt文件。该文件定义了哪些内容可以被抓取,哪些不可以。遵循这些规则不仅是出于道德考虑,也是避免法律问题的重要举措。因此,在爬取前,务必检查目标网站的robots.txt文件,确保遵从相关规定。
结论
phpSnoopy为网站数据提取提供了强大的支持。通过合理设置请求头、控制抓取频率、建立错误处理机制、有效解析数据以及遵守robots.txt规则,用户可以高效地进行自动化网站数据提取。在实践中,随着不断的试错与调整,用户会逐渐找到最适合自身需求的抓取策略。最终,利用phpSnoopy抓取的数据将为各类分析、决策提供有力支持,使得数据驱动的决策成为可能。

相关文章