无监督学习:在这种类型的学习中,算法会使用未标记的数据进行训练。没有标签或输出的数据。算法的任务是发现数据中的模式或结构。

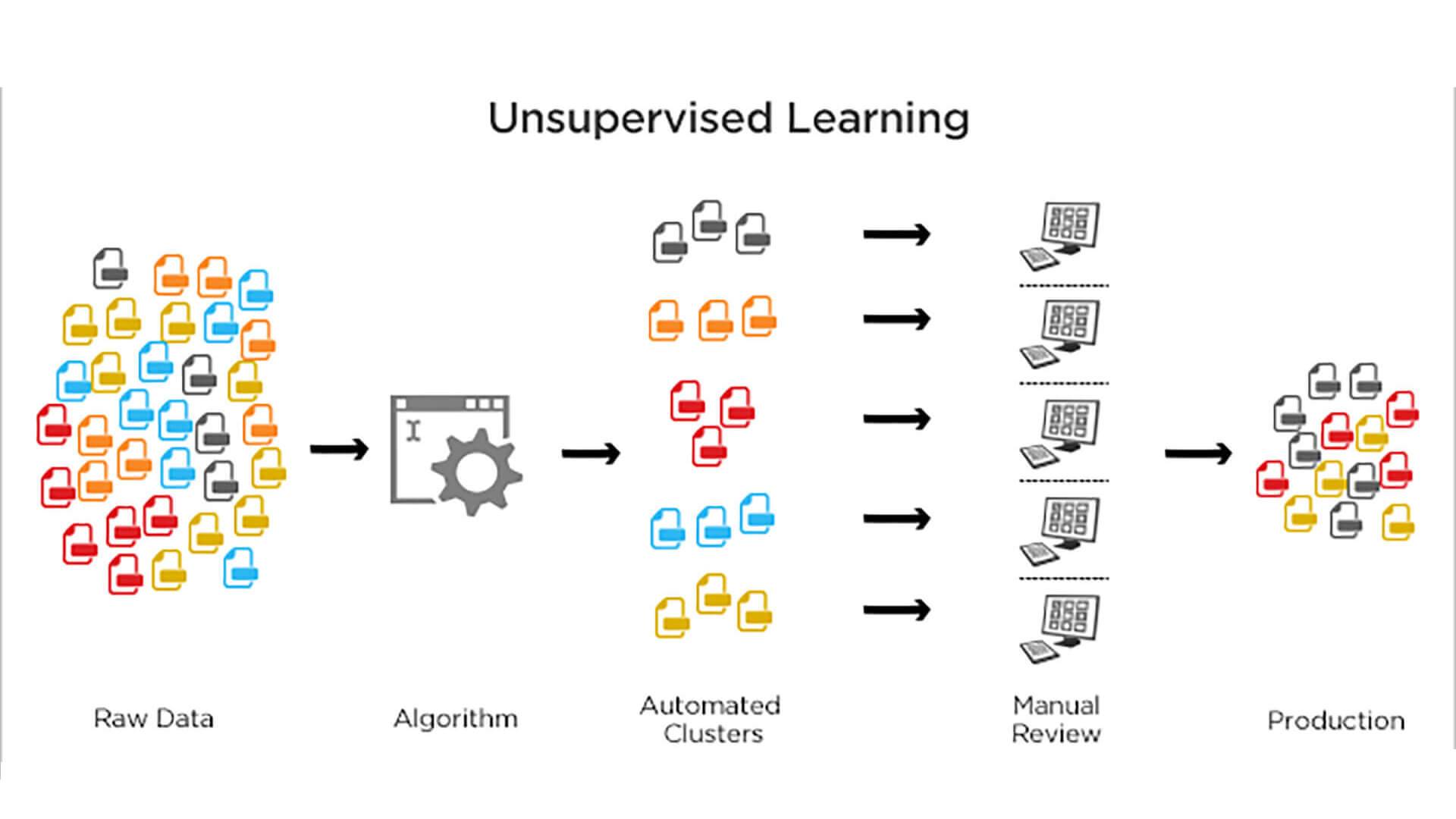
无监督学习是一种机器学习方法,它使用未标记的数据进行训练。这意味着输入的数据不包含标签或输出,算法的任务是发现数据中的模式或结构。
无监督学习的技术
无监督学习可以使用各种技术,包括:
- 聚类:将数据点分组到不同的簇中,每个簇包含具有相似特征的数据点。
- 降维:将高维数据转换为低维数据,同时保留原始数据的关键特征。
- 异常检测:识别与正常数据不同的数据点,这些数据点可能表示异常或欺诈。
无监督学习的优点
无监督学习具有以下优点:
- 可以用于探索和理解数据,而无需人工标记。
- 可以发现隐藏的模式和关系,这些模式和关系可能无法通过有监督学习发现。
- 对于大型、复杂的数据集特别有用,因为手动标记数据可能是不可行的。
无监督学习的应用
无监督学习被广泛应用于各种领域,包括:
- 客户细分和市场研究:通过识别客户群体的不同特征和偏好。
- 图像处理:通过图像分割、对象检测和人脸识别。
- 自然语言处理:通过文本聚类、主题建模和情感分析。
- 异常检测:通过识别欺诈交易、网络入侵和医疗异常。
- 推荐系统:通过预测用户可能感兴趣的产品或内容。
无监督学习的挑战
无监督学习也面临着一些挑战,包括:
- 找到正确的无监督学习算法和超参数以获得最佳结果。
- 解释算法发现的模式和结构,因为它们可能复杂且难以理解。
- 缺乏基准指标来评估无监督学习模型的性能。
结论
无监督学习是一种强大的机器学习方法,可用于探索和理解未标记的数据。它可以发现隐藏的模式和关系,并且在标记数据成本高或不可行的情况下特别有用。虽然无监督学习面临着一些挑战,但它仍然是解决各种实际问题的宝贵工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

好狗导航是全网最优质的电影导航。及时收录影视、音乐、小说、游戏等分类的网址和内容,让您的观影生活更简单精彩。看电影,从好狗电影导航开始。